Web Scraping คืออะไรและทำงานอย่างไรในโลกดิจิทัล
ข้อมูล(Data)และข้อมูลเป็นคำสองคำที่มักใช้แทนกันได้ แต่มีความแตกต่างที่โดดเด่นระหว่างคำเหล่านี้ ตัวอย่างเช่น data หมายถึงบิตของข้อมูล แต่ไม่ใช่ข้อมูลเอง ในทางกลับกันข้อมูล(Information)คือชุดของข้อมูลที่ได้รับการประมวลผลอย่างมีความหมาย ด้วยข้อมูลที่มีอยู่อย่างล้นหลามบนอินเทอร์เน็ต วิธีการต่างๆ เช่นWeb Scraping , Web HarvestingหรือWeb Data Extractionถูกนำมาใช้เพื่อสร้างข้อมูลเชิงลึกที่นำไปใช้ได้จริงและเปลี่ยนแปลงเกมผ่านการใช้อินเทอร์เน็ต (Internet)แต่สิ่งที่พวกเขาหมายถึงในโลกออนไลน์ มาดูกัน!
Web Scraping ทำงานอย่างไร
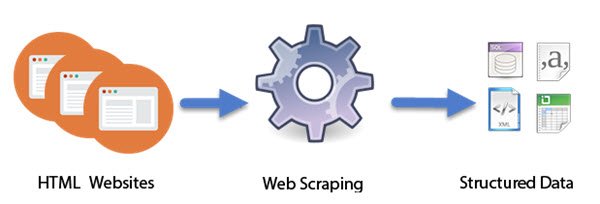
โปรแกรม คอมพิวเตอร์(Computer)ที่ออกแบบมาเป็น บอท อัจฉริยะ(Intelligent)ทำงานของWeb Scraping (Web Scraping)ซึ่งแตกต่างจากการขูดหน้าจอ ซึ่งจะคัดลอกเฉพาะพิกเซลที่แสดงบนหน้าจอเท่านั้น การขูดเว็บจะดึงโค้ด HTML(HTML) ที่ซ่อนอยู่ และด้วยข้อมูลดังกล่าวที่จัดเก็บไว้ในฐานข้อมูล วิธีการนี้ได้รับความนิยมค่อนข้างมาก ถือเป็นหนึ่งในทักษะที่จำเป็นอย่างยิ่งที่จะได้รับในโลกดิจิทัลในปัจจุบัน มีแอพพลิเคชั่นที่ยอดเยี่ยมในการรวบรวมชุดข้อมูลขนาดใหญ่ ซึ่งเป็นพื้นฐานของเทคนิคต่างๆ เช่น
- การวิเคราะห์ข้อมูลขนาดใหญ่(Big Data Analytics)
- การเรียนรู้ของเครื่อง
- ปัญญาประดิษฐ์(Artificial Intelligence)
ด้วยการขยายตัวอย่างรวดเร็วของข้อมูลดิจิทัล การเข้าถึงBig Dataผ่านWeb ScrapingหรือWeb Data Extractionกลายเป็นเรื่องง่าย ต้องบอกว่าWeb Scrapingสามารถใช้กับธุรกิจดิจิทัลที่ต้องอาศัยการรวบรวมข้อมูลในทั้งสอง กรณี ถูกกฎหมาย(Legitimate)หรือไม่ชอบด้วยกฎหมาย ก่อนหน้านี้รวมถึงตัวอย่าง Web Scraping(Benevolent Web Scraping Examples)ที่เป็นประโยชน์ในขณะที่ตัวอย่างหลังมีตัวอย่าง Web Scraping ที่เป็น อันตราย(Malicious Web Scraping)
ตัวอย่างการขูดเว็บที่เป็นประโยชน์
- บอทของเครื่องมือ ค้นหา(Search)รวบรวมข้อมูลเว็บไซต์ วิเคราะห์เนื้อหาเพื่อกำหนดอันดับตามการค้นพบบางอย่างเช่นGoogle
- ไซต์เปรียบเทียบ ราคา(Price)ที่ปรับใช้บอทเพื่อดึงราคาผลิตภัณฑ์โดยอัตโนมัติ
- บริษัทวิจัย ตลาด(Market)ที่ใช้เครื่องขูดเพื่อดึงข้อมูลจากโซเชียลมีเดีย (เช่น สำหรับการวิเคราะห์ความรู้สึก ความชอบส่วนบุคคล ฯลฯ)
ตัวอย่างการขูดเว็บที่เป็นอันตราย
Web Scrapingเพื่อจุดประสงค์ที่ผิดกฎหมายอาจก่อให้เกิดความสูญเสียทางการเงินอย่างรุนแรงหากข้อมูลถูกดึงออกมาโดยไม่ได้รับอนุญาตจากเจ้าของเว็บไซต์ กรณีการใช้งานMalicious Web Scraping ที่พบบ่อยที่สุดสองกรณีคือการขูด ราคาและการขโมยเนื้อหา
- การขูดราคา(Price Scraping) – บอท Scraperตรวจสอบฐานข้อมูลธุรกิจที่แข่งขันกันเพื่อเข้าถึงข้อมูลการกำหนดราคา ตัดราคาคู่แข่ง และเพิ่มยอดขาย
- การขโมยเนื้อหา(Content Theft) – กิจกรรมที่ผิดกฎหมายนี้ประกอบด้วยการขโมยเนื้อหาขนาดใหญ่จากเว็บไซต์เป้าหมาย เป้าหมายโดยทั่วไป ได้แก่ แคตตาล็อกผลิตภัณฑ์ออนไลน์และเว็บไซต์ที่ใช้เนื้อหาดิจิทัลเพื่อขับเคลื่อนธุรกิจ
หวังว่านี่จะช่วยได้!

About the author
ฉันเป็นผู้เชี่ยวชาญด้าน Windows และทำงานในอุตสาหกรรมซอฟต์แวร์มากว่า 10 ปี ฉันมีประสบการณ์กับทั้งระบบ Microsoft Windows และ Apple Macintosh ทักษะของฉัน ได้แก่ การจัดการหน้าต่าง ฮาร์ดแวร์คอมพิวเตอร์และเสียง การพัฒนาแอพ และอื่นๆ ฉันเป็นที่ปรึกษาที่มีประสบการณ์ซึ่งสามารถช่วยให้คุณได้รับประโยชน์สูงสุดจากระบบ Windows ของคุณ
Related posts
ไม่มี Internet Connectivity แต่แสดงให้เห็นว่าเชื่อมต่อกับ Web
Bitcoin คืออะไร Digital Currency
เกิดอะไรขึ้นกับ Online Accounts เมื่อคุณตาย: Digital Assets Management
Dark Web or Deep Web คืออะไร? วิธีการ Access & Precautions
ประโยชน์ของการใช้ Digital Detox และวิธีการไปเกี่ยวกับมัน
Setup Internet Radio Station ฟรีบน Windows PC
ปิดใช้งาน Internet Explorer 11 เป็น standalone browser โดยใช้ Group Policy
วิธีการหาหรือตรวจสอบที่ link or URL redirects ถึง
วิธีประหยัดพลังงานแบตเตอรี่ขณะท่องเว็บใน Internet Explorer
วิธีปลดบล็อกและเข้าถึง Blocked หรือเว็บไซต์ที่ถูก จำกัด
Edge and Store ปพลิเคชันไม่ได้เชื่อมต่อกับ Internet - Error 80072EFD
Surfers vs Website เจ้าของ vs ad blockers vs Anti Ad Blockers War
วิธีการปรับเปลี่ยนหรือเปลี่ยนการตั้งค่า WiFi Router ของคุณ?
10 ตัวอย่างเว็บ 3.0: เป็นอนาคตของอินเทอร์เน็ตหรือไม่
Cybercrime และการจัดหมวดหมู่ - การจัดระเบียบและไม่มีการรวบรวมกัน
Internet crash ทั้งหมดสามารถ มากเกินไปสามารถนำไปสู่ Internet ได้มากเกินไป?
Group Speed Dial สำหรับ Firefox: สำคัญ Internet Sites ที่ Your Fingertips
โยกย้ายจาก Internet Explorer ถึง Edge โดยใช้เครื่องมือเหล่านี้อย่างรวดเร็ว
วิธีใช้ Shared Internet Connection ที่บ้าน
ตรวจสอบว่า Internet Connection ของคุณมีความสามารถในการสตรีมเนื้อหา 4K