ดาวน์โหลดเว็บไซต์ทั้งหมดใน Firefox โดยใช้ ScrapBook
ต้องการบันทึกหน้าเว็บหรือเว็บไซต์เพื่อให้คุณสามารถดูแบบออฟไลน์ได้(Need to save a webpage or website so that you can view it offline)หรือไม่ คุณจะออฟไลน์เป็นเวลานาน แต่ต้องการเรียกดูเว็บไซต์โปรดของคุณได้หรือไม่ หากคุณใช้Firefoxแสดงว่ามีส่วน เสริมของ Firefoxที่สามารถแก้ปัญหาของคุณได้
ScrapBookเป็นส่วนขยายของ Firefox(Firefox extension) ที่ยอดเยี่ยม ที่ช่วยให้คุณบันทึกหน้าเว็บ(web page)และจัดระเบียบมันด้วยวิธีการจัดการที่ง่ายมาก สิ่งที่ยอดเยี่ยมจริงๆ เกี่ยวกับส่วนเสริมนี้คือมันเบามาก รวดเร็ว และแคชสำเนาของหน้าเว็บ(web page) ในเครื่องได้อย่างแม่นยำ เกือบจะสมบูรณ์แบบและรองรับหลายภาษา ฉันทดสอบกับหน้าเว็บหลายหน้าที่(web page)มีกราฟิกจำนวนมากและ สไตล์ CSS(CSS) แฟนซี และรู้สึกยินดีเป็นอย่างยิ่งที่เห็นว่าเวอร์ชันออฟไลน์ดูเหมือนกับเวอร์ชันออนไลน์ทุกประการ
คุณสามารถใช้ScrapBookเพื่อวัตถุประสงค์ต่อไปนี้:
- บันทึกหน้าเว็บเดียว
- บันทึกตัวอย่างหรือบางส่วน ของ (Save snippet or portion)หน้าเว็บ(Web page)เดียว
- บันทึกทั้งเว็บไซต์
- จัดระเบียบคอลเลกชันในลักษณะเดียวกับที่คั่นหน้า(Bookmarks)กับโฟลเดอร์, โฟลเดอร์ย่อย
- การค้นหา ข้อความแบบเต็ม(Full text)และการค้นหาการกรองอย่างรวดเร็วของคอลเลกชันทั้งหมด
- การแก้ไขเว็บเพจที่รวบรวมไว้
- Text/HTML editที่คล้ายกับ Notes ของ Opera
การติดตั้ง ScrapBook
หากคุณกำลังใช้ Firefox(Firefox)เวอร์ชันล่าสุดซึ่งก็คือ v33 สำหรับฉันในขณะที่เขียนบทความนี้ คุณจะต้องปรับการตั้งค่าบางอย่างเพื่อให้คุณสามารถใช้ScrapBookได้อย่างถูกต้อง ตามค่าเริ่มต้นไอคอน ScrapBook(ScrapBook icon)จะไม่ปรากฏ(t show)ที่ใด ดังนั้นวิธีเดียวที่คุณสามารถใช้ได้คือถ้าคุณคลิกขวาบนหน้าเว็บ เพิ่มปุ่มลงในแถบเครื่องมือหรือเมนูโดยคลิกขวาที่ใดก็ได้บนแถบเครื่องมือแล้วเลือกปรับแต่ง(Customize)

ในหน้าจอปรับแต่ง(Customize screen)คุณจะเห็นไอคอนสมุด(ScrapBook icon)ภาพทางด้านซ้ายมือ ไปข้างหน้าและลากไปที่แถบเครื่องมือที่ด้านบนหรือไปที่เมนู จากนั้นไปข้างหน้าและคลิกที่ปุ่มออกจากการปรับแต่ง(Exit Customize)

ก่อนที่เราจะใช้ งาน ScrapBookเพื่อบันทึกเว็บไซต์ คุณอาจต้องการเปลี่ยนการตั้งค่าสำหรับส่วนเสริม คุณสามารถทำได้โดยคลิกที่ปุ่มเมนู(menu button)ที่ด้านบนขวา (สามเส้นแนวนอน) จากนั้นคลิกที่Add -on(Add-ons)

ตอนนี้คลิกที่ส่วนขยาย(Extensions)แล้วคลิก ปุ่ม ตัวเลือก(Options)ถัดจากโปรแกรม เสริม ของScrapBook(ScrapBook add-on)

คุณสามารถเปลี่ยนแป้นพิมพ์ลัด ตำแหน่งที่จัดเก็บข้อมูล และการตั้งค่าย่อยอื่นๆ ได้ที่นี่

ใช้ ScrapBook เพื่อดาวน์โหลดไซต์
มาดูรายละเอียดการใช้งานโปรแกรมกันจริง ๆ กันดีกว่า ขั้นแรก(First)ให้โหลดเว็บไซต์ที่คุณต้องการดาวน์โหลดหน้าเว็บ วิธีที่ง่ายที่สุดในการเริ่มดาวน์โหลดคือ คลิกขวาที่ใดก็ได้บนหน้าแล้วเลือกบันทึกหน้า(Save Page)หรือบันทึกหน้าเป็น(Save Page As)ทางด้านล่างของเมนู สองตัวเลือก นี้ถูกเพิ่มโดยScrapBook

บันทึกหน้า(Save Page)จะช่วยให้คุณเลือกโฟลเดอร์แล้วบันทึกหน้าปัจจุบันโดยอัตโนมัติเท่านั้น ถ้าคุณต้องการตัวเลือกเพิ่มเติม ซึ่งปกติฉันทำ ให้คลิกที่ ตัวเลือก บันทึกหน้า(Save Page)เป็น คุณจะได้รับกล่องโต้ตอบอื่นซึ่งคุณสามารถเลือกและเลือกตัวเลือกมากมาย
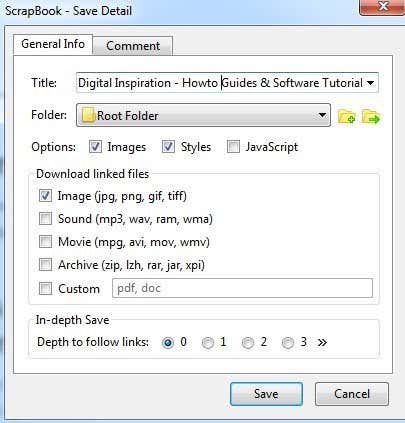
ส่วนที่สำคัญ ได้แก่ส่วนตัวเลือก(Options)ดาวน์โหลดไฟล์ที่เชื่อมโยง(Download linked files)และ ตัวเลือกบันทึกในเชิงลึก (In-depth Save)ตามค่าเริ่มต้นScrapBookจะดาวน์โหลดรูปภาพและรูปแบบ แต่คุณสามารถเพิ่มJavaScriptได้หากเว็บไซต์ต้องการให้ทำงานได้อย่างถูกต้อง
ส่วนดาวน์โหลด(Download)ไฟล์ที่เชื่อมโยง จะดาวน์โหลดเฉพาะภาพที่เชื่อมโยง แต่คุณยังสามารถดาวน์โหลดไฟล์เสียง ไฟล์ภาพยนตร์ ไฟล์เก็บถาวร หรือระบุประเภทไฟล์ที่ต้องการดาวน์โหลด นี่เป็นตัวเลือกที่มีประโยชน์จริงๆ หากคุณอยู่ในเว็บไซต์ที่มีลิงก์จำนวนมากไปยังไฟล์บางประเภท ( Word docs , PDFsฯลฯ ) และคุณต้องการดาวน์โหลดไฟล์ที่เกี่ยวข้องทั้งหมดอย่างรวดเร็ว
สุดท้ายนี้ ตัวเลือกการ บันทึกในเชิงลึก(In-depth Save)คือวิธีที่คุณจะดาวน์โหลดเว็บไซต์ขนาดใหญ่ขึ้น โดยค่าเริ่มต้น จะมีการตั้งค่าเป็น 0 ซึ่งหมายความว่าจะไม่ติดตามลิงก์ใดๆ ไปยังหน้าอื่นๆ ในไซต์หรือลิงก์อื่นๆ สำหรับเรื่องนั้น หากคุณเลือกอย่างใดอย่างหนึ่ง ระบบจะดาวน์โหลดหน้าปัจจุบันและทุกอย่าง(page and everything)ที่เชื่อมโยงจากหน้านั้น ความลึก(Depth)ของ 2 จะดาวน์โหลดจากหน้าปัจจุบัน หน้าที่เชื่อมโยงที่ 1 และลิงก์ใดๆ จากหน้าที่เชื่อมโยงที่ 1 ด้วย

คลิก(Click)ปุ่มบันทึก(Save button)และหน้าต่างใหม่จะปรากฏขึ้นและหน้าต่างๆ จะเริ่มดาวน์โหลด คุณจะต้องกดปุ่มPauseทันที แล้วฉันจะบอกคุณว่าทำไม หากคุณปล่อยให้ScrapBookทำงาน จะเริ่มดาวน์โหลดทุกอย่างจากหน้าเว็บ รวมถึงเนื้อหาทั้งหมดในซอร์สโค้ด(source code)ที่อาจเชื่อมโยงไปยังเว็บไซต์หรือเครือข่ายโฆษณาอื่นๆ ดังที่คุณเห็นในภาพด้านบน นอกเว็บไซต์หลัก (labnol.org) มีการดาวน์โหลดโฆษณาจากgoogleadservices.com และบางอย่าง(googleadservices.com and something)จาก ctrlq.org
คุณต้องการให้โฆษณาแสดงบนไซต์ในขณะที่คุณกำลังเรียกดูแบบออฟไลน์หรือไม่? การทำ เช่นนี้จะเสียเวลาและแบนด์วิดธ์(time and bandwidth) เป็นจำนวนมาก ดังนั้นสิ่งที่ดีที่สุดที่ควรทำคือกดPauseแล้วคลิกปุ่มตัวกรอง(Filter)

สองตัวเลือกที่ดีที่สุดคือจำกัดเฉพาะโดเมน(Restrict to Domain)และ จำกัด เฉพาะไดเรกทอรี (Restrict to Directory)โดยปกติสิ่งเหล่านี้จะเหมือนกัน แต่ในบางไซต์จะแตกต่างกัน หากคุณทราบแน่ชัดว่าต้องการหน้าใด คุณยังสามารถกรองตามสตริงและพิมพ์URL ของคุณ เอง ตัวเลือกนี้ยอดเยี่ยมเพราะจะกำจัดขยะอื่น ๆ ทั้งหมดและดาวน์โหลดเฉพาะเนื้อหาจากเว็บไซต์จริงที่คุณเข้าชมมากกว่าจากเว็บไซต์โซเชียลมีเดีย เครือข่ายโฆษณา ฯลฯ
ไปข้างหน้าและคลิกเริ่ม(Start)และหน้าต่างๆ จะเริ่มดาวน์โหลด เวลาในการดาวน์โหลดจะขึ้นอยู่กับ ความเร็วใน การเชื่อมต่ออินเทอร์เน็ต(Internet connection) ของคุณ และจำนวนเว็บไซต์ที่คุณกำลังดาวน์โหลด ส่วนเสริมใช้งานได้ดีกับเว็บไซต์ส่วนใหญ่ และปัญหาเดียวที่ฉันพบคือในบางไซต์URL(URLs) ที่ พวกเขาใช้เชื่อมโยงไปยังเนื้อหาของพวกเขาเองเป็นURL(URLs) ที่ สมบูรณ์
ปัญหาของURL(URLs) แบบสัมบูรณ์ คือเมื่อคุณเปิดหน้าดัชนี(index page)ในFirefoxขณะออฟไลน์และพยายามคลิกลิงก์ใดๆ ก็ตาม ระบบจะพยายามโหลดจากเว็บไซต์จริงแทนที่จะโหลดจากแคชในเครื่อง ในกรณีดังกล่าว คุณต้องเปิดไดเร็กทอรีดาวน์โหลด(download directory)และเปิดหน้าต่างๆ ด้วยตนเอง เป็นเรื่องที่เจ็บปวดและฉันเคยเกิดขึ้นกับเว็บไซต์เพียงไม่กี่แห่ง แต่ก็เกิดขึ้นแล้ว คุณสามารถดูโฟลเดอร์ดาวน์โหลดได้(download folder)โดยคลิกที่ปุ่ม ScrapBook(ScrapBook button)บนแถบเครื่องมือของคุณ จากนั้นคลิกขวาที่ไซต์และเลือก(site and choosing) เครื่องมือ(Tools) – แสดงไฟล์(Show Files)

ใน Explorer ให้จัดเรียงตามประเภท(Type)แล้วเลื่อนลงไปที่ไฟล์ที่เรียกว่าเอกสาร HTML (HTML Document. )โดยปกติหน้าเนื้อหาจะเป็นไฟล์ default_00x ไม่ใช่ไฟล์ index_00x

หากคุณไม่ได้ใช้Firefoxและยังต้องการดาวน์โหลดหน้าเว็บลงในคอมพิวเตอร์ของคุณ คุณยังสามารถตรวจสอบซอฟต์แวร์ที่ชื่อว่าWinHTTrack ซึ่งจะดาวน์โหลดเว็บไซต์(web site) ทั้งหมดโดยอัตโนมัติ เพื่อเรียกดูแบบออฟไลน์ในภายหลัง อย่างไรก็ตามWinHTTrackใช้พื้นที่ในปริมาณที่เหมาะสม ดังนั้นตรวจสอบให้แน่ใจว่าคุณมีพื้นที่ว่างเพียงพอบนฮาร์ดไดรฟ์ของคุณ
ทั้งสองโปรแกรมทำงานได้ดีสำหรับการดาวน์โหลดทั้งเว็บไซต์หรือสำหรับการดาวน์โหลดหน้าเว็บเดียว ในทางปฏิบัติ แทบจะเป็นไปไม่ได้เลยที่จะดาวน์โหลดทั้งเว็บไซต์เนื่องจากมีลิงก์จำนวนมากที่สร้างโดยซอฟต์แวร์ CMS(CMS software)เช่นWordPressเป็นต้น หากคุณมีคำถามใดๆ ให้โพสต์ความคิดเห็น สนุก!

About the author
ฉันเป็นมืออาชีพด้านการรีวิวซอฟต์แวร์ที่มีประสบการณ์มากกว่า 10 ปี ฉันได้เขียนและตรวจสอบซอฟต์แวร์ประเภทต่างๆ มากมาย รวมถึงแต่ไม่จำกัดเพียง Microsoft Office (Office 2007, 2010, 2013), แอป Android และเครือข่ายไร้สาย ทักษะของฉันอยู่ที่การจัดเตรียมการทบทวนโปรแกรม/แอปพลิเคชันโดยละเอียดและมีวัตถุประสงค์เพื่อให้ผู้อื่นใช้เป็นเอกสารอ้างอิงหรือสำหรับงานของตนเอง ฉันยังเป็นผู้เชี่ยวชาญเกี่ยวกับผลิตภัณฑ์ MS office และมีคำแนะนำเกี่ยวกับวิธีการใช้งานอย่างมีประสิทธิภาพและประสิทธิผล
Related posts
3 ส่วนขยาย VPN Chrome ที่ดีที่สุดสำหรับการท่องเว็บอย่างปลอดภัย
5 แอพที่ดีที่สุดในการดาวน์โหลดเพลงฟรีบน Android
10 สุดยอดเว็บเบราว์เซอร์เพื่อความเป็นส่วนตัวในปี 2022
4 ที่ดีที่สุดที่มีน้ำหนักเบาเบราว์เซอร์สำหรับ Windows and Mac
คืออะไร Discord Nitro และมันคุ้มค่าหรือไม่
6 Best Pregnancy Apps ของ 2021
12 Best Free Android Calculator Apps and Widgets
21 สุดยอด Time Management Tools and Apps คุณต้องลอง
6 Ways ถึง Animate Still Photos Online Or กับ Apps
Autohotkey Tutorial ถึง Automate Windows Tasks
4 Best Apps ถึง Remotely View A Webcam บน iOS and Android
7 Best Apps ที่จะช่วยให้คุณศึกษาที่ดีขึ้น
10 add-on และส่วนขยาย Firefox ที่ดีที่สุด
6 Best Reddit Alternatives คุณสามารถใช้ฟรี
Google Tasks กับ Google Keep: ซึ่งเป็น Better?
5 Best Spotify Alternatives สำหรับ Music Streaming
6 ใบหน้าที่ดีที่สุด Swap Apps สำหรับ Mobile Or PC
คืออะไร BetterDiscord and How การติดตั้งมันได้หรือไม่
Twitch Turbo คืออะไรและคุ้มค่าหรือไม่
Intego Antivirus Review: ที่มีประสิทธิภาพ แต่คุณลักษณะที่ จำกัด